
Introduction
In our final year, my team and I built what we thought was a simple student blog platform. We had a frontend, a backend, and a PostgreSQL database. Simple right?
It was until we started adding more features, file uploads, Redis caching, background jobs, and email verification, it started becoming a small-scale distributed system.
We were fighting with five containers, deploying manually, and duct-taping logs together just to debug things
We started with Docker Compose, but soon realized its limits. When our app traffic grew, we needed auto-scaling to handle it smoothly. And since Kubernetes is the industry standard, learning it was important not just for the project, but to prepare us for real-world jobs after graduation.
That’s when we discovered Kubernetes✨
At first, it felt like overkill. But once we saw how it handled restarts, service discovery, updates, and scaling all out of the box, it just clicked. It didn’t just make our app production-ready. It made us better engineers.
If you’re a software engineer who’s heard of Kubernetes but isn’t quite sure what it does or whether it’s for you, this blog is for you.
We’ll break down everything you need to know to get started, without using big marketing words.
What is Kubernetes?
Imagine you run a food truck chain (Tacos, Burger, Hot Dog, etc). Each food truck is like a “container” that runs your Tacos or Burger business (it runs one application), but if you have a lot of food trucks across different cities you will need to make sure:
- Each food truck has the right ingredients (Config & Dependencies)
- If a food truck breaks down a new one should automatically replace it
- Customers are directed to the closest/least busy food truck (load balancing)
- You can open more food trucks during rush hour and scale down when its quite (auto scaling)
This is where Kubernetes comes in
Kubernetes is an orchestrator of your food trucks. It:
- Keeps track of all your parking lots (nodes) and the food trucks (containers) inside them
- Ensures your food trucks are running as planned (desired state management).
- This is called the Kubernetes Resource Model, where you define what you want (e.g. “3 taco trucks”), and Kubernetes makes it happen automatically using controllers.
- Automatically replaces or restarts trucks that stop working (self-healing)
- Distributes customer traffic efficiently (service discovery and load balancing)
- Helps you roll out new recipes without downtime (rolling updates)
But if you read our last blog about Docker, you might ask what is the difference between Docker Compose and Kubernetes
Docker Compose vs Kubernetes
Docker Compose:
Imagine you are managing a few food trucks at a local fair. You set them up with a simple checklist:
- One makes tacos
- One makes burgers
- One serves drinks.
You know exactly where they are, and if one stops working you fix it manually
- You use a single list (docker-compose.yml) to tell each food truck what to do.
- It’s quick and easy to set up and tear down.
- Great for testing recipes or small events (Apps)
Kubernetes:
But when your business grows to be in multiple cities, with hundreds of trucks, you will need more than a checklist. That’s where Kubernetes shines.
Instead of managing each truck:
- It orchestrates everything automatically
- Ensures trucks are running with the right ingredients
- Replaces broken trucks without you noticing
- Distributes customers efficiently
- Scales up or down based on demand
Kubernetes is perfect for large-scale, production-ready infrastructure that needs automation, self-healing, and high availability.
One more difference is that Docker Compose runs all containers on a single machine, while Kubernetes abstracts away the underlying servers (nodes), letting you deploy and manage containerized applications as workloads without worrying about which server runs what. It was designed for scaling, resilience, and managing distributed systems, enabling developers to focus on their apps
Now that we understand what is the difference between Docker Compose and Kubernetes, let’s take a look at the core concepts of Kubernetes:
- Cluster
- Node
- Pod
- Deployment
- ReplicaSet
- Service
- Namespace
- ConfigMap & Secret
- Volume
It can be overwhelming, I know but let’s take it step by step. Let’s start with the building blocks of Kubernetes.
Main Kubernetes Concepts
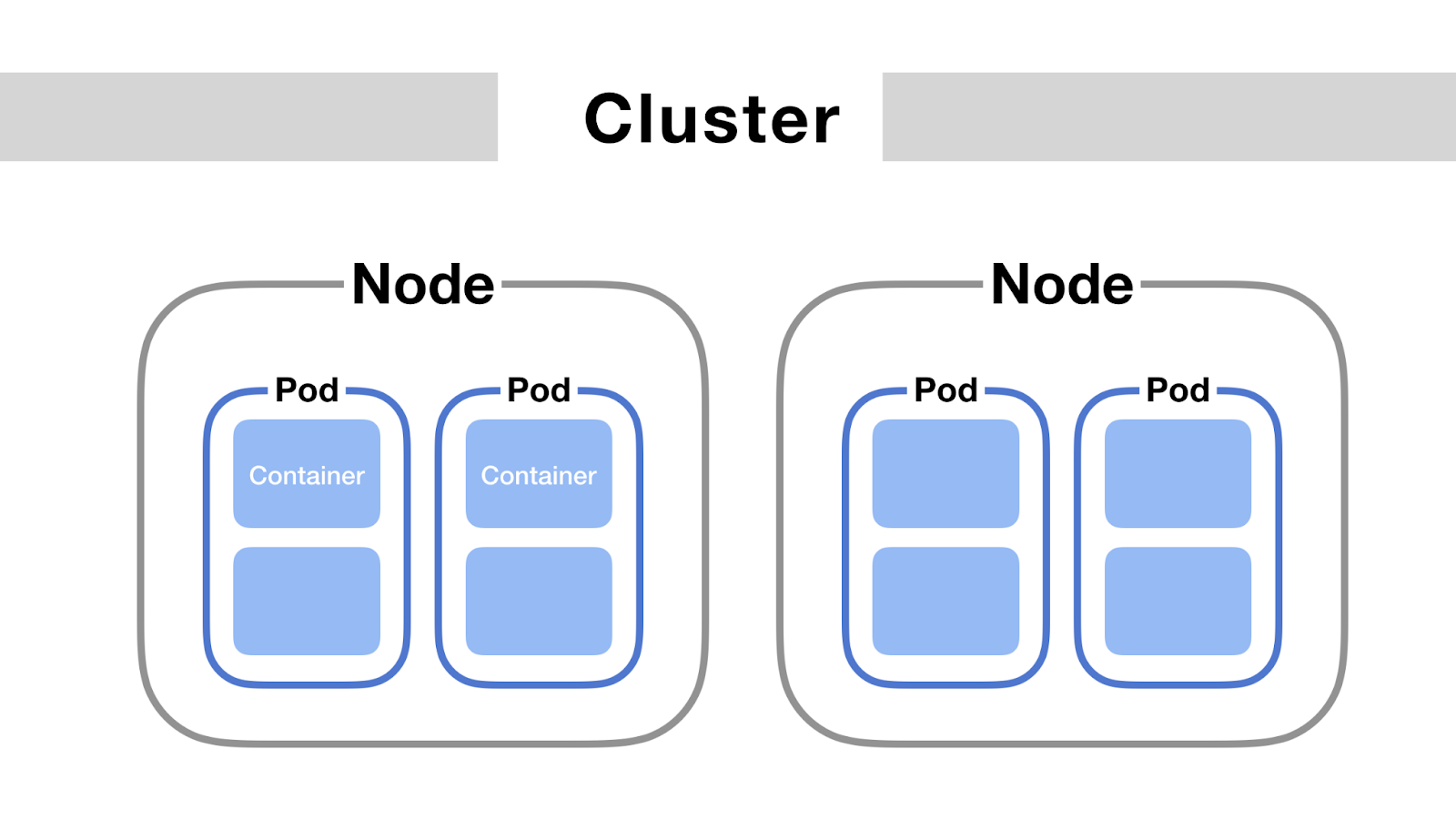
Cluster:
it is the entire system that runs your containerized applications, and it consists of nodes
Node
Control Plane Node:
It is like the headquarters office (it controls the entire cluster)
- It decides which city gets more food trucks (scheduling)
- keeps records of where every truck is and what it’s serving (API server, etcd)
- Ensures everything runs as planned, sending out new trucks if one breaks down (controller manager).
Worker Nodes
These are your actual food trucks, which follow instructions from headquarters (master node). Make tacos, burgers, or hot dogs (run pods). have a small team inside ensuring food is made (kubelet), orders are routed (kube-proxy), and ingredients are used to cook (container runtime).
Don’t worry, we will explain all that in more detail later on.
Pods
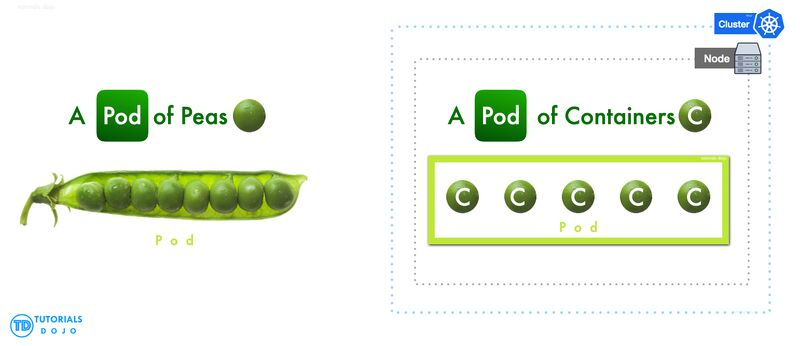
Each food truck (worker node) serves pods, which are like kitchen setups inside the truck
A pod can have:
- One container (e.g., taco station).
- Multiple containers working together (e.g., burger grill + drink dispenser in one pod sharing storage and space).
Deployment
It tells Kubernetes how to run and manage your pods.
- Example:
Always have 3 taco trucks running in the city.
Service
It provides a stable IP address and DNS name to access a set of pods. It makes sure that the traffic is automatically load balanced across the pods, even if pods are deleted, or replaced, so clients can always reach your application without worrying about pod IP changes.
- Example:
Its like your customer hotline or website where people order food. They don’t care which exact truck cooks it the Service routes their order to any available truck (pod)
Namespace
It is used to logically group resources within your cluster.
- Example:
It’s a way to have different brands in your food business, although the trucks are everywhere, they’re logically grouped by namespaces- Brand for Taco (namespace: tacos)
- Brand for Burger (namespace: Burger)
ConfigMap & Secret
ConfigMap:
Stores non-sensitive configuration data (e.g., environment variables, URLs).
Secret:
Stores sensitive data (e.g., passwords, API keys) in a secure way.
Volume
It provides persistent storage to pods so the containers don’t lose their data when its restarted
Now you can finally understand the language your DevOps teammates speak but how does Kubernetes work behind the scenes?
Kubernetes Architecture
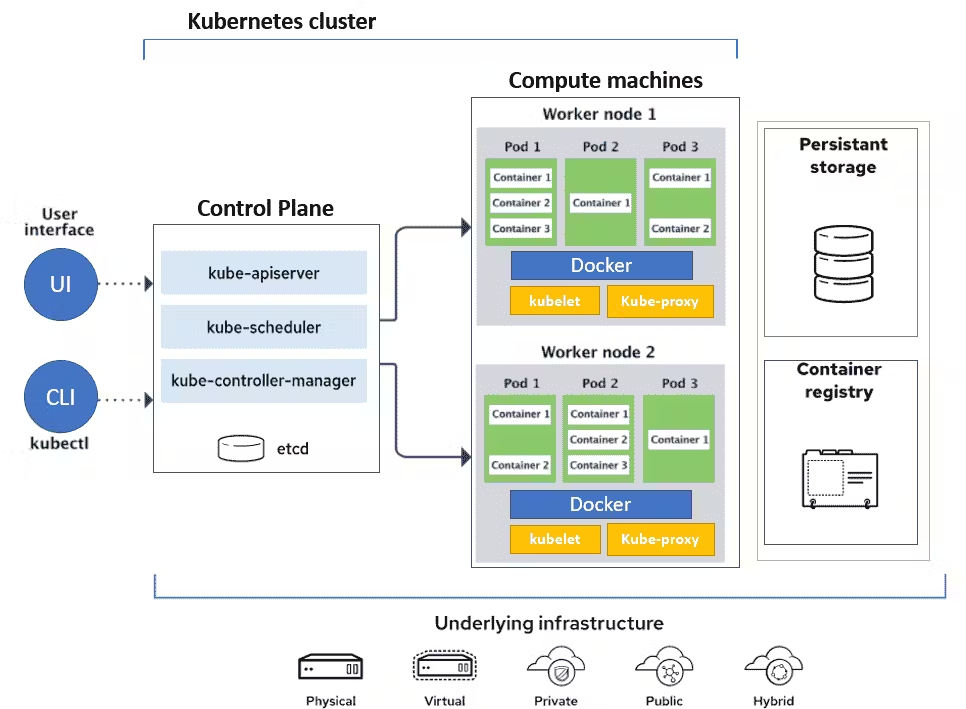
Control Plane (The Brain of Kubernetes)
API Server
It is the main entry point for your Kubernetes cluster. It receives requests from the kubectl commands, external tools like CI/CD pipelines, etc…
Scheduler
When you deploy a new pod, the Scheduler decides where it will run in the cluster.
Controller Manager
If a pod crashes, the Controller Manager notices and creates a replacement pod automatically.
Etcd
It’s a key-value store that holds all the data that your cluster needs, like
- Cluster State
- Configuration Data
- Secrets
- ConfigMaps
- Namespaces
- Roles and Permissions
- Network Policies
Node Components
Kubelet
Each node has a kubelet, which receives the pod’s instructions from the control plane, and then starts the container, and then makes sure it stays healthy and running as expected.
Kube-proxy
Kubeproxy makes sure that traffic is routed correctly to the pods, no matter where they run.
container runtime
It runs your containers.
But still, how does all of this work together? Like how does Kubernetes know what to run and how to run it?
How does Kubernetes work?

Kubernetes Manifest
It is a YAML or JSON file that describes the desired state of your application or resources in Kubernetes.
It tells Kubernetes what you want:
- How many pods do you want running
- What container images to use
- What ports to expose
- What environment variables to set
- How to connect services
Let’s take an example with Stakpak.dev just open stakpak and sign up and start a newflow and then ask it to “Create a deployment”
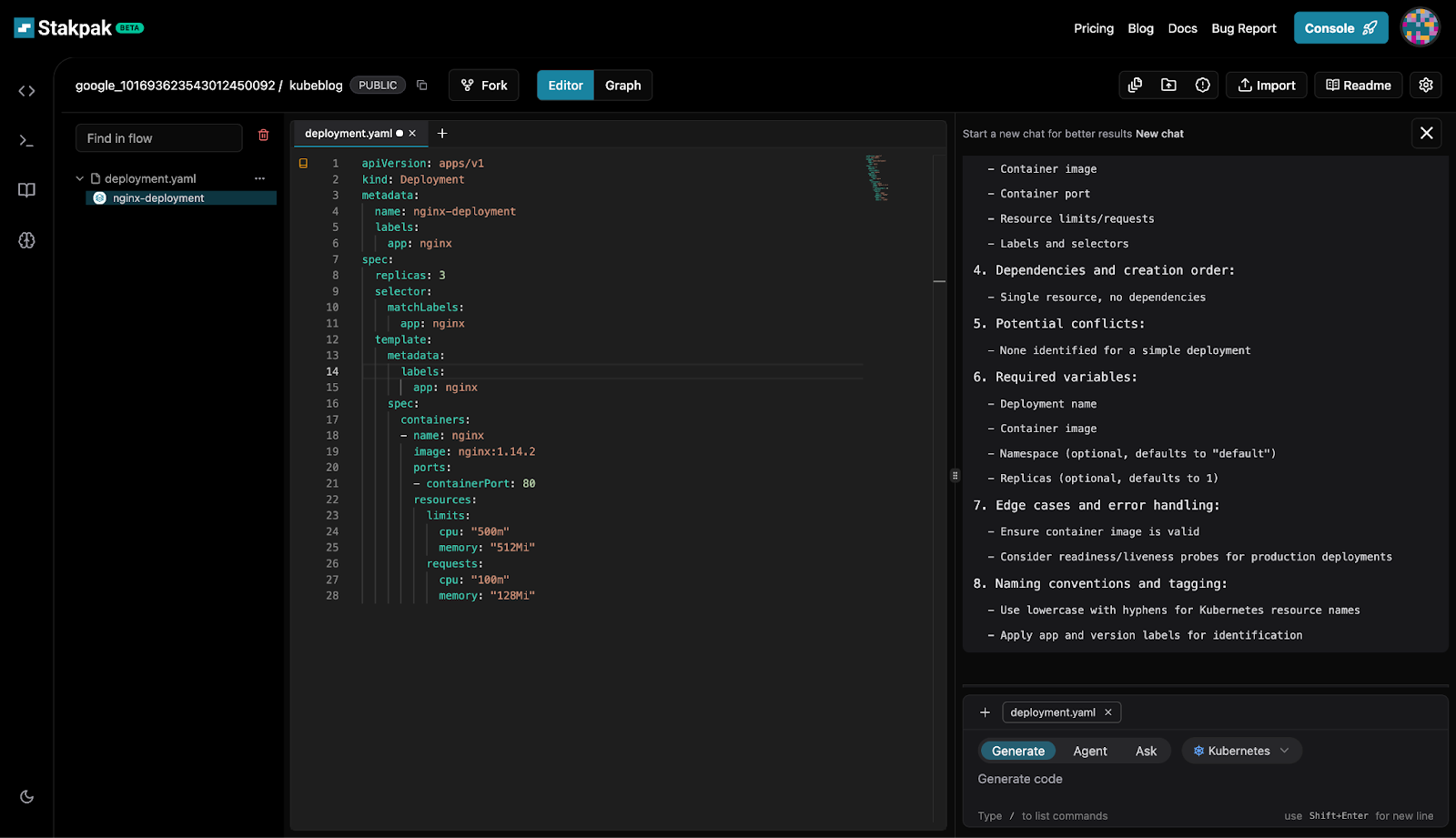
As you can see this Manifest file tells Kubernetes to run three Nginx pods. Each pod uses the nginx:1.14.2 image and listens on port 80. It sets resource limits so each pod can use up to 500 milli-cpu and 512Mi of memory, but it will get at least 100 milli-cpu and 128Mi.
The deployment is called nginx-deployment, and it uses labels to keep track of the pods it manages.
It makes sure there are always three Nginx containers running with the right resources.
Now that you’ve learned about Kubernetes, you can see why it’s such a powerful tool. Using Kubernetes when you don’t need it can overcomplicate simple projects. As Spider-Man said, “With great power comes great responsibility.”

TL;DR:
This TLDR was generated with stakpak
- Docker Compose is great for simple projects with a few containers.
- Kubernetes is like a powerful orchestrator, perfect for large, scalable apps needing automation, self-healing, and high availability.
- Core concepts include Clusters, Nodes, Pods, Deployments, ReplicaSets, Services, Namespaces, ConfigMaps, Secrets, and Volumes.
- The control plane manages your cluster (API Server, Scheduler, Controller Manager, etcd), while nodes run your app containers.
- You define what you want using Kubernetes manifests (YAML files), and Kubernetes makes it happen automatically.
- Use Kubernetes wisely – it’s powerful, but can overcomplicate small projects.