So I remember I was working in a start-up, and I was the only one in the team doing DevOps work in that start up and my manager asked me to set up our CI/CD pipeline. I knew nothing back then about CI/CD, I was excited to be like those cool engineers who talk about their “fancy” automated workflows until I realized I had to deal with Config Files, SSH keys, Webhooks, and the builds that fail for alien reasons🤡
That’s why I decided to write this blog, it’s to help people who are setting up their first CI/CD pipeline, so they don’t suffer like I did, and so we have high-quality software
Before we start, let’s first see what CI/CD is and why we need it.
The World Before CI/CD
After writing the code, the developers had to build and zip the code and upload it to a shared drive for the QA to install it on an identical test machine, Testing was informal, mostly exploratory with communication happening face to face or by using post it notes, once QA signed off, the code was merged into a master branch, Releases required weeks or months, just enough time to burn CDs for customers. Without tags or branches, devs froze master during this phase. Meanwhile, they accumulated large changes in personal branches, leading to painful merges. Bugs were often blamed on others or dismissed, with testers taking most of the accountability.
Can you imagine how tense the relationship was between Dev and QA? I mean, it’s still tense, but back then it was worse

Continuous Integration (CI) gained popularity around 1999 to 2001, while Continuous Delivery (CD) really took off after 2010, coinciding with the rise of DevOps and cloud-native tools.
But what is CI/CD?
Continuous Integration (CI) means frequently committing code, running “automated” builds, and testing to catch issues before they appear. Continuous Deployment (CD) automates pushing code to production. This seems like it would boost productivity, right? It does, but it also increased the security attack surface and a lot of things can go wrong.
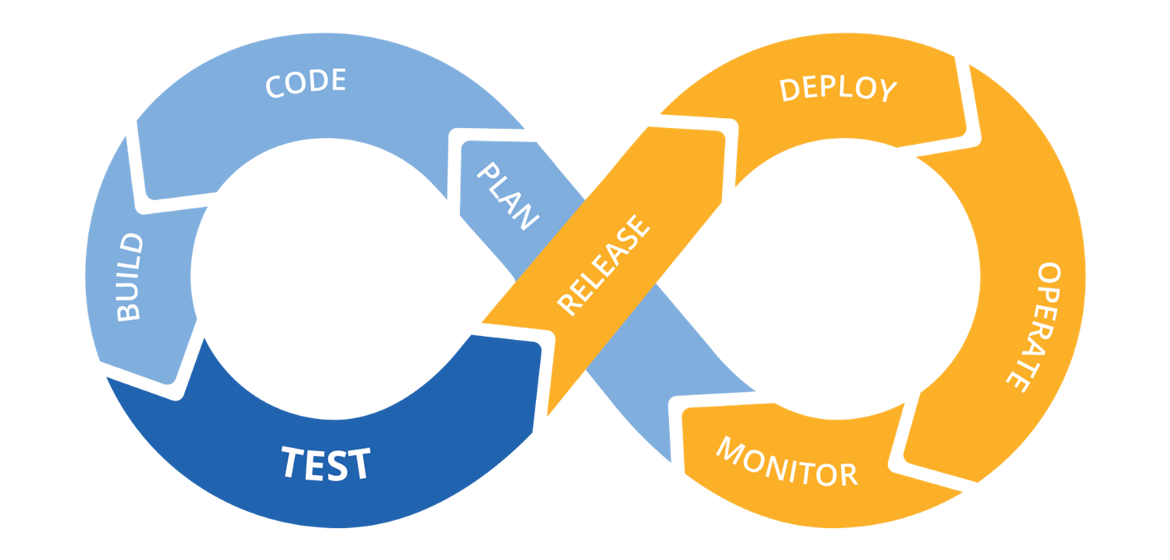
A CI/CD pipeline is made up of multiple stages that automate the process of building, testing, and deploying code.
Let’s take a look at the stages:
- Source Stage:
It usually starts with a trigger that starts the pipeline, which can be you pushing the code to a version control system like Git (e.g., GitHub, GitLab). - Build Stage:
In this stage, we compile and package the code (e.g., compiling Java, creating the Docker images) - Testing Stage:
Once the build is ready, we run automated tests to catch any issues early. These tests can include unit tests for individual functions, integration tests for how parts of the system work together, and end-to-end (E2E) tests that mimic real user actions. - Deployment Stage:
Now we are ready to deploy. In this stage, we either deploy what we built into a staging/production environment - Monitoring & Feedback:
Last but not least, we monitor what we deployed to make sure that everything is working as expected
In each stage, we use a lot of tools to help us automate and make everything easier, tools like GitHub, Docker, npm, Kubernetes, GitHub Actions, Prometheus, Grafana, and a lot more (according to the 2024 GitLab DevSecOps survey, 41% of developers use at least 6 tools)
Overwhelming, I know, but don’t worry! I’ll tell you exactly what to do later.
Now that we know what CI/CD is and how it stopped the pre-CI/CD world chaos, let’s take a look at the mistakes that I made setting up my first pipeline as the only Cloud Engineer in the company.
Keep It Simple Stupid:

There is a famous principle in software engineering called KISS, or keep it simple, stupid. You don’t need a fancy pipeline that has every tool and feature for every CI/CD pipeline; it’s important to keep your pipeline simple.
Start with a basic setup like build → test → deploy to a staging environment, and iterate as needs grow. Or in other words, start simple but plan for scale so you don’t suffer like I did.
When I was setting up my first pipeline, I think I might have over-engineered it a little bit 🤏🏻, I was so excited to try everything I learned, and guess what, this led to me spending hours debugging a webhook that wasn’t even necessary 🤡
Learn The Tools:
I know the picture is overwhelming, but you don’t need to learn all of that; you don’t need to boil the ocean. Remember, Keep It Simple, Stupid (KISS)! Pick the most suitable tool for you, for example, GitHub Actions if you already use GitHub to host your code, and before you write any config files take some time to go through a crash course (YouTube or just annoy your DevOps friends), also take some time to go through the official docs (you’d be surprised how useful the docs are).
Trust me, this might sound like a lot of time, but this will save you whole nights of fighting with, I mean, debugging a YAML file
You can also use Stakpak, and it will generate all the files you need based on the official docs, but still, you are an Engineer, not a copy-paste script kiddie. You need to understand everything so you don’t suffer trying to fix the build if it breaks in the future
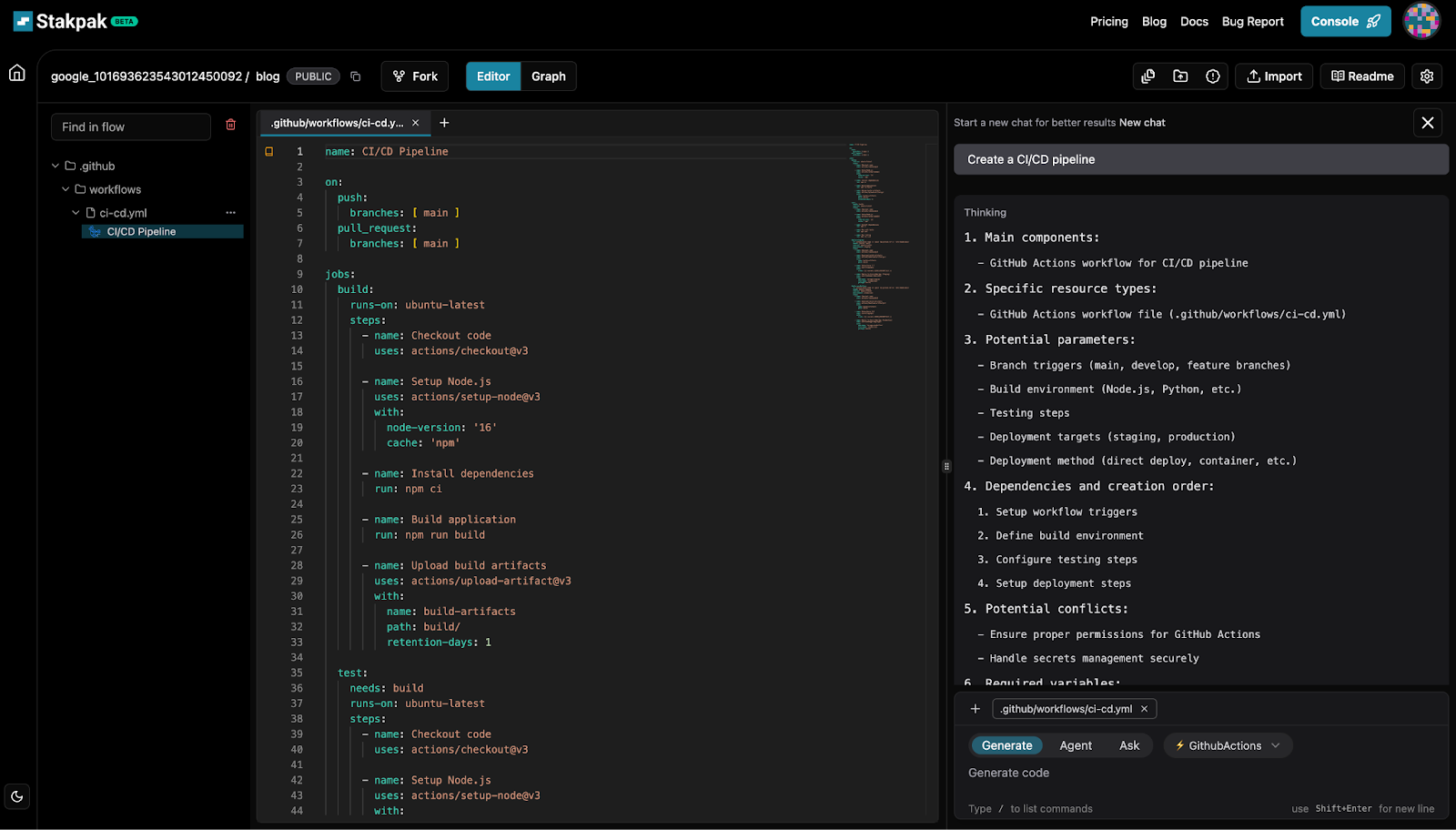
Prompt: Create a GitHub Actions CI/CD pipeline
Don’t Blindly Trust Automation
All of these fancy tools and automation might seem like magic it’s not, though. Builds always break for silly reasons, like missing dependencies, a typo in a script, or a webhook not triggering. I remember spending a night debugging a build, only to find out that it had a missing environment variable
That’s why it’s important to have logs so you can trace the failures
Test Your Pipeline Like You Test Your Code
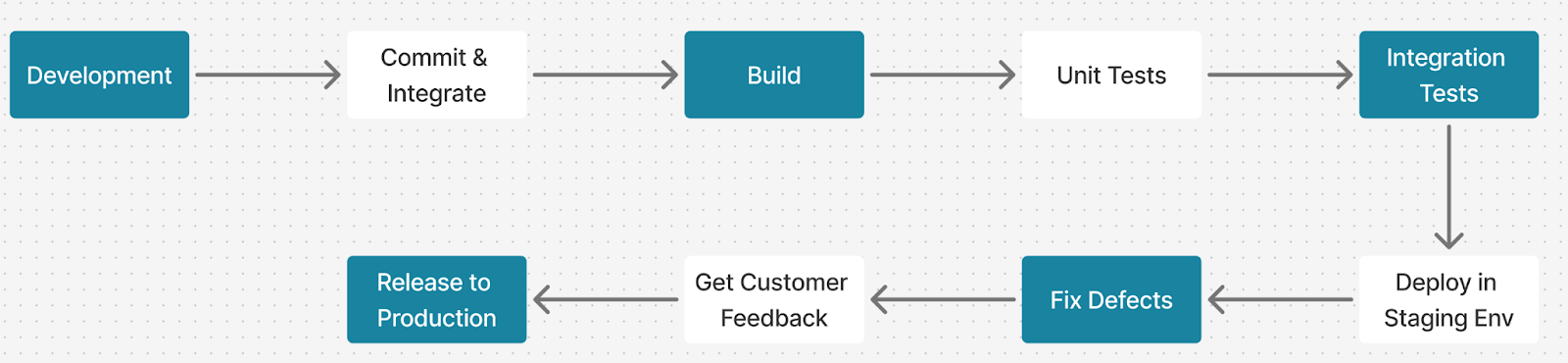
A pipeline is just a bunch of config files that have code, and like any code, it needs testing and validation, so I really recommend having a staging pipeline. Why?
So imagine this: a typo in your GitHub Actions workflow pushes broken code to your staging server, leaving the team blocked for hours while you run all over the place trying to fix it. Treat your pipeline like your application code, and test it every step of the way.
Security Isn’t an After Thought
Isn’t it ironic that I’m ending with security? (Was it an afterthought?) This usually happens irl too, people rarely give security the importance it deserves, they either forget all about it or think about it when it’s too late
Your CI/CD pipeline security is really important, as it might waste all your team’s effort. CI/CD is the gate for your infrastructure; people leave SSH keys in public repos, which is like giving your house keys to a thief. That’s why it’s important to use a secret manager and not to hard-code any secrets. I really recommend checking the OWASP Top 10 CI/CD Security Risks to learn more about how to secure your CI/CD
And last but not least, remember that security is everyone’s job, even Developers, not just security engineers
TL;DR:
This TLDR was generated with stakpak
- Start simple! Don’t over-engineer your first pipeline—get build → test → (staging) deploy working before adding complexity.
- Take time to learn the tools (e.g., GitHub Actions, Jenkins) and read some docs/crash courses—even a little bit upfront saves a ton of debugging later.
- Don’t blindly trust automation. Builds fail for silly reasons—always check logs!
- Test your pipeline like your code—use staging, validate pipeline changes before pushing to production.
- Make security a priority from the start. Use secret managers, NEVER hard-code credentials, and check out CI/CD security risks (OWASP Top 10).
- Iterate as you grow. Keep the KISS principle in mind and adapt as your needs change.